
http://spark.apache.org/docs/1.6.0/api/scala/index.html#org.apache.spark.rdd.PairRDDFunctions
val words = Array("one", "two", "two", "three", "three", "three") val wordPairsRDD = sc.parallelize(words).map(word => (word, 1)) val wordCountsWithReduce = wordPairsRDD.reduceByKey(_ + _) val wordCountsWithGroup = wordPairsRDD.groupByKey().map(t => (t._1, t._2.sum)) reduceByKey(func: (V,V) => V, numPartitions: Int): RDD[(K,V)]
reduceByKey用于对每个key对应的多个value进行本地先merge操作,并且merge操作可以通过函数自定义
groupByKey(numPartitions: Int): RDD[(K,Iterable[V])]
groupByKey也是对每个key进行操作,但是只生成一个sequence。如果需要对sequence进行aggregation操作时,groupByKey本身是不能自定义操作函数的。
(1) 采用reduceByKey时,spark可以在每个分区shuffle之前,将待输出的数据与一个共用的key结合。即在shuffle之前调用lamdba函数,先计算一遍。等shuffle候,再执行lamdba函数。减少了shuffle过程的数据量。
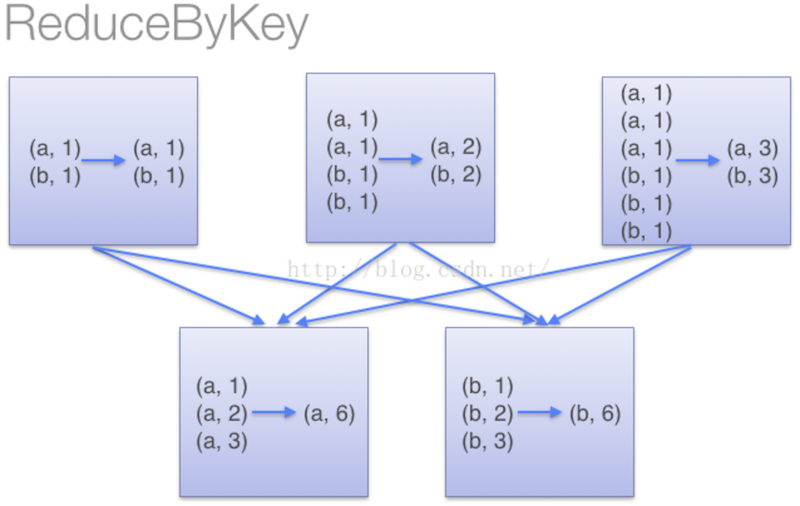
(2)groupByKey 不接受lamdba函数,spark只能shuffle所有的k-v pair.之后再调用lamdba函数计算。造成了集群节点之间的开销很大。
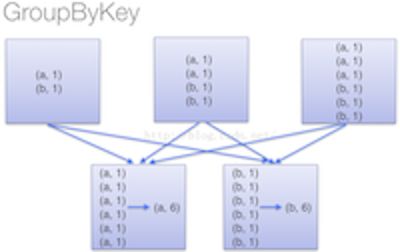
注意:
(1)在对进行复杂计算时,reduceByKey优于groupByKey
(2)如果仅仅是group处理,那么以下函数应该优先于 groupByKey
(1)、combineByKey 组合数据,但是组合之后的数据类型与输入时值的类型不一样。
(2)、foldByKey合并每一个 key 的所有值,在级联函数和“零值”中使用。